

Generated: 2026-07-25 12:54:32 UTC
This page compares each AI translation prompt version against the best available human translation for the same lemma, using the automated MT metric set from Zainaldin et al. 2026: BLEU-4, chrF++, METEOR, ROUGE-L, BERTScore, COMET, and BLEURT. Length regression and residual tables remain as local diagnostics for translation-length drift.
Inputs: one representative AI run per lemma and prompt version, preferring the current preferred source text, with status completed or approved, non-empty translation text, and 100 Kappa rows from Gabe's final review tracker export. Full translation texts are used for metrics but are not printed on these pages.
The paper metric set is BLEU-4, chrF++, METEOR, ROUGE-L, BERTScore, COMET, and BLEURT. Lexical metrics run locally. BERTScore needs the bert-score package, COMET needs unbabel-comet, and BLEURT needs the BLEURT package plus a local checkpoint path in BLEURT_CHECKPOINT.
| Metric | Status for this run |
|---|---|
| BLEU-4 | SacreBLEU sentence BLEU-4 |
| chrF++ | SacreBLEU chrF++ with word_order=2 |
| METEOR | NLTK METEOR with WordNet synonyms |
| ROUGE-L | rouge-score ROUGE-L with stemming |
| BERTScore | unavailable: sidecar invocation failed (Command '['/home/stephanos/metric-envs/neural-metrics/bin/python', '/home/stephanos/stephanos/compute_neural_translation_metrics.py']' timed out after 7200 seconds) |
| COMET | unavailable: sidecar invocation failed (Command '['/home/stephanos/metric-envs/neural-metrics/bin/python', '/home/stephanos/stephanos/compute_neural_translation_metrics.py']' timed out after 7200 seconds) |
| BLEURT | unavailable: sidecar invocation failed (Command '['/home/stephanos/metric-envs/neural-metrics/bin/python', '/home/stephanos/stephanos/compute_neural_translation_metrics.py']' timed out after 7200 seconds) |
This is the paper-facing 100-row Kappa corpus from Gabe's final review tracker, not the broader approved-human translation pool.
For ordinary ChatGPT v3, 97 of 100 Kappa rows have at least one guidance match, with 1,191 total run-guidance links.
| Prompt | Pairs | BLEU-4 | chrF++ | METEOR | ROUGE-L | Corpus BLEU | 3-gram F1 | 4-gram F1 | Exact | <=2 char edits |
|---|---|---|---|---|---|---|---|---|---|---|
| gpt-5.5 v1 | 100 | 25.1% | 53.7% | 56.0% | 58.4% | 26.6% | 20.7% | 13.0% | 0 | 1 |
| gpt-5.5 v2 | 100 | 51.9% | 72.4% | 77.3% | 78.0% | 48.5% | 42.3% | 32.9% | 2 | 4 |
| gpt-5.5 v3 | 100 | 57.6% | 77.2% | 80.8% | 81.2% | 56.0% | 49.5% | 40.9% | 6 | 10 |
| claude_fable_5 v1 | 100 | 27.5% | 58.3% | 66.0% | 67.9% | 33.0% | 26.4% | 17.4% | 0 | 0 |
| claude_fable_5 v2 | 100 | 54.3% | 74.4% | 78.1% | 79.1% | 49.8% | 43.2% | 33.8% | 2 | 4 |
| claude_fable_5 v3 | 100 | 58.2% | 77.4% | 81.9% | 82.1% | 55.9% | 49.4% | 40.2% | 3 | 6 |
Each row compares the same Kappa lemmas under two prompt versions. Positive deltas mean the later prompt scored higher.
| Comparison | Metric | Pairs | Mean delta | Paired t p | Wins | Losses | Ties |
|---|---|---|---|---|---|---|---|
| v1->v2 | BLEU-4 | 100 | 26.8% | 2.91e-27 | 96 | 4 | 0 |
| v1->v2 | chrF++ | 100 | 18.7% | 1.84e-28 | 96 | 4 | 0 |
| v1->v2 | METEOR | 100 | 21.3% | 1.27e-26 | 95 | 4 | 1 |
| v1->v2 | ROUGE-L | 100 | 19.6% | 9.47e-31 | 97 | 2 | 1 |
| v1->v2 | 3-gram F1 | 100 | 27.3% | 4.99e-25 | 93 | 5 | 2 |
| v1->v2 | 4-gram F1 | 100 | 26.0% | 1.94e-21 | 92 | 6 | 2 |
| v2->v3 | BLEU-4 | 100 | 5.7% | 0.0009 | 62 | 33 | 5 |
| v2->v3 | chrF++ | 100 | 4.8% | 8.90e-07 | 68 | 30 | 2 |
| v2->v3 | METEOR | 100 | 3.5% | 0.0004 | 64 | 31 | 5 |
| v2->v3 | ROUGE-L | 100 | 3.2% | 0.0002 | 62 | 30 | 8 |
| v2->v3 | 3-gram F1 | 100 | 7.2% | 0.0005 | 65 | 30 | 5 |
| v2->v3 | 4-gram F1 | 100 | 8.6% | 0.0004 | 64 | 31 | 5 |
| v1->v3 | BLEU-4 | 100 | 32.5% | 4.09e-30 | 98 | 2 | 0 |
| v1->v3 | chrF++ | 100 | 23.5% | 2.61e-35 | 100 | 0 | 0 |
| v1->v3 | METEOR | 100 | 24.8% | 7.39e-30 | 98 | 2 | 0 |
| v1->v3 | ROUGE-L | 100 | 22.8% | 2.69e-33 | 99 | 1 | 0 |
| v1->v3 | 3-gram F1 | 100 | 34.5% | 4.31e-27 | 97 | 2 | 1 |
| v1->v3 | 4-gram F1 | 100 | 34.6% | 4.60e-24 | 96 | 2 | 2 |
This section uses every completed run from gpt-5.5_v3_repeat. It is separated from the main prompt-comparison table because the question is variance across repeated model samples, not mean performance of another prompt.
| Corpus row | Lemma ID | Headword | Runs | Distinct outputs | BLEU range | BLEU values | ROUGE range | ROUGE values | chrF range | chrF values | AI words |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2,054 | Καβαλίς | 5 | 5 | 10.4% | 1: 66.5%; 2: 76.7%; 3: 68.9%; 4: 76.8%; 5: 72.5% | 3.3% | 1: 85.3%; 2: 86.2%; 3: 85.5%; 4: 87.3%; 5: 84.0% | 4.4% | 1: 80.4%; 2: 82.9%; 3: 80.0%; 4: 84.4%; 5: 82.2% | 1: 64.000; 2: 65.000; 3: 66.000; 4: 61.000; 5: 66.000 |
| 2 | 2,055 | Καβασσός | 5 | 5 | 7.2% | 1: 42.4%; 2: 42.2%; 3: 35.3%; 4: 38.7%; 5: 42.5% | 7.8% | 1: 72.6%; 2: 68.6%; 3: 64.8%; 4: 70.1%; 5: 71.1% | 6.1% | 1: 66.3%; 2: 64.5%; 3: 61.9%; 4: 64.1%; 5: 68.1% | 1: 106.000; 2: 101.000; 3: 104.000; 4: 105.000; 5: 102.000 |
| 3 | 2,056 | Καβειρία | 5 | 5 | 5.4% | 1: 44.6%; 2: 42.4%; 3: 45.6%; 4: 40.2%; 5: 41.7% | 4.9% | 1: 77.0%; 2: 73.9%; 3: 74.1%; 4: 72.1%; 5: 72.6% | 3.9% | 1: 73.3%; 2: 72.0%; 3: 74.8%; 4: 70.9%; 5: 72.7% | 1: 101.000; 2: 99.000; 3: 104.000; 4: 96.000; 5: 100.000 |
| 4 | 2,057 | Καβελλιών | 5 | 4 | 20.8% | 1: 42.2%; 2: 42.2%; 3: 48.0%; 4: 60.9%; 5: 40.1% | 14.5% | 1: 83.6%; 2: 83.6%; 3: 92.3%; 4: 93.9%; 5: 79.4% | 12.0% | 1: 73.0%; 2: 73.0%; 3: 78.5%; 4: 81.6%; 5: 69.6% | 1: 33.000; 2: 33.000; 3: 31.000; 4: 32.000; 5: 34.000 |
| 5 | 2,058 | Καβύλη | 5 | 3 | 8.8% | 1: 67.4%; 2: 70.0%; 3: 76.2%; 4: 70.0%; 5: 70.0% | 4.3% | 1: 95.7%; 2: 91.3%; 3: 95.7%; 4: 91.3%; 5: 91.3% | 3.6% | 1: 85.9%; 2: 85.3%; 3: 88.8%; 4: 85.3%; 5: 85.3% | 1: 23.000; 2: 23.000; 3: 23.000; 4: 23.000; 5: 23.000 |
| 6 | 2,059 | Καδμεία | 5 | 5 | 7.7% | 1: 44.1%; 2: 42.5%; 3: 50.2%; 4: 44.1%; 5: 46.2% | 9.8% | 1: 78.0%; 2: 76.2%; 3: 78.0%; 4: 82.9%; 5: 73.2% | 2.2% | 1: 69.3%; 2: 69.1%; 3: 71.3%; 4: 70.4%; 5: 69.1% | 1: 21.000; 2: 22.000; 3: 21.000; 4: 21.000; 5: 21.000 |
This table only covers active prompt-comparison experiments. Retired temperature attempts and Parallage prompt-spectrum translations are excluded from the measured website because they are not part of the paper-facing metric comparison.
| Family | Variants | Evaluated pairs | Notes |
|---|---|---|---|
| Main ChatGPT paper prompts | 3 | 300 | Core v1/v2/v3 comparison. |
| External Claude variants | 9 | 800 | Imported from external workspaces; rows stay non-public by default. |
| v4 reasoning/mini experiments | 6 | 406 | Active slow experiment lanes; several still have open requests. Repeated runs are reported separately above. |
| Prompt | Active | API mode | Reasoning | Requested runs | Completed runs | Completed lemmas | Evaluated Kappa pairs | Open requests | Status |
|---|---|---|---|---|---|---|---|---|---|
| claude_fable_5 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_fable_5 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_fable_5 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_opus_4_8 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_opus_4_8 v2 | yes | chat_completions | 1 | 0 | 0 | 0 | 0 | Tracked Claude variant has no complete imported Kappa comparison yet. | |
| claude_opus_4_8 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_sonnet_5 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_sonnet_5 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| claude_sonnet_5 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | External Claude import complete for the Kappa corpus. | |
| gpt-4.1-2025-04-14 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4.1-2025-04-14 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4.1-2025-04-14 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-05-13 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-05-13 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-05-13 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-08-06 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-08-06 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-08-06 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-11-20 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-11-20 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4o-2024-11-20 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4-turbo-2024-04-09 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4-turbo-2024-04-09 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-4-turbo-2024-04-09 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.1 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.1 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.1 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.2 v1 | yes | chat_completions | 1 | 113 | 109 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.2 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.2 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.3-chat-latest v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.3-chat-latest v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.3-chat-latest v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.4 v1 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.4 v2 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.4 v3 | yes | chat_completions | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. | |
| gpt-5.5 v1 | no | chat_completions | 1 | 101 | 101 | 100 | 0 | Main ChatGPT prompt series for the paper. | |
| gpt-5.5 v2 | no | chat_completions | 1 | 102 | 102 | 100 | 0 | Main ChatGPT prompt series for the paper. | |
| gpt-5.5 v3 | yes | chat_completions | 1 | 2,015 | 380 | 100 | 0 | Main ChatGPT prompt series for the paper. | |
| gpt-5.5_v4_mini v1 | yes | responses | low | 1 | 101 | 101 | 100 | 0 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.5_v4_mini_high v1 | yes | responses | high | 1 | 101 | 101 | 100 | 0 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.5_v4_mini_medium v1 | yes | responses | medium | 1 | 101 | 101 | 100 | 0 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.5_v4_reasoning v1 | yes | responses | low | 1 | 42 | 42 | 42 | 1 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.5_v4_reasoning_high v1 | yes | responses | high | 1 | 32 | 32 | 32 | 11 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.5_v4_reasoning_medium v1 | yes | responses | medium | 1 | 32 | 32 | 32 | 11 | Active Responses API experiment with reasoning effort set on the profile. |
| gpt-5.6-sol v1 | yes | responses | medium | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. |
| gpt-5.6-sol v2 | yes | responses | medium | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. |
| gpt-5.6-sol v3 | yes | responses | medium | 1 | 100 | 100 | 100 | 0 | Tracked prompt profile. |
The dedicated timeline analysis compares 12 OpenAI model releases across 3 fixed Stephanos prompt versions on the same 100-row Kappa paper corpus. 36 of 36 model-prompt sets are complete.
Open the model-timeline charts, projections, and detailed table.
Passage length is measured as the source Greek token count when source text is available, falling back to human translation word count only when a source passage has no Greek tokens. Each row regresses one metric against passage length for one prompt version.
Across 432 evaluable metric/prompt regressions, negative correlations are more common: 43 positive, 389 negative, and 0 flat. Using p < 0.05, 0 are significantly positive and 317 are significantly negative.
Open the full metric vs passage length page.
Zainaldi et al.'s Galen translation is represented here by its reported mean passage length of 220.5 words. The Stephanos values below are raw ordinary-least-squares predictions from the metric-vs-passage-length regressions above; they are not clamped to metric bounds.
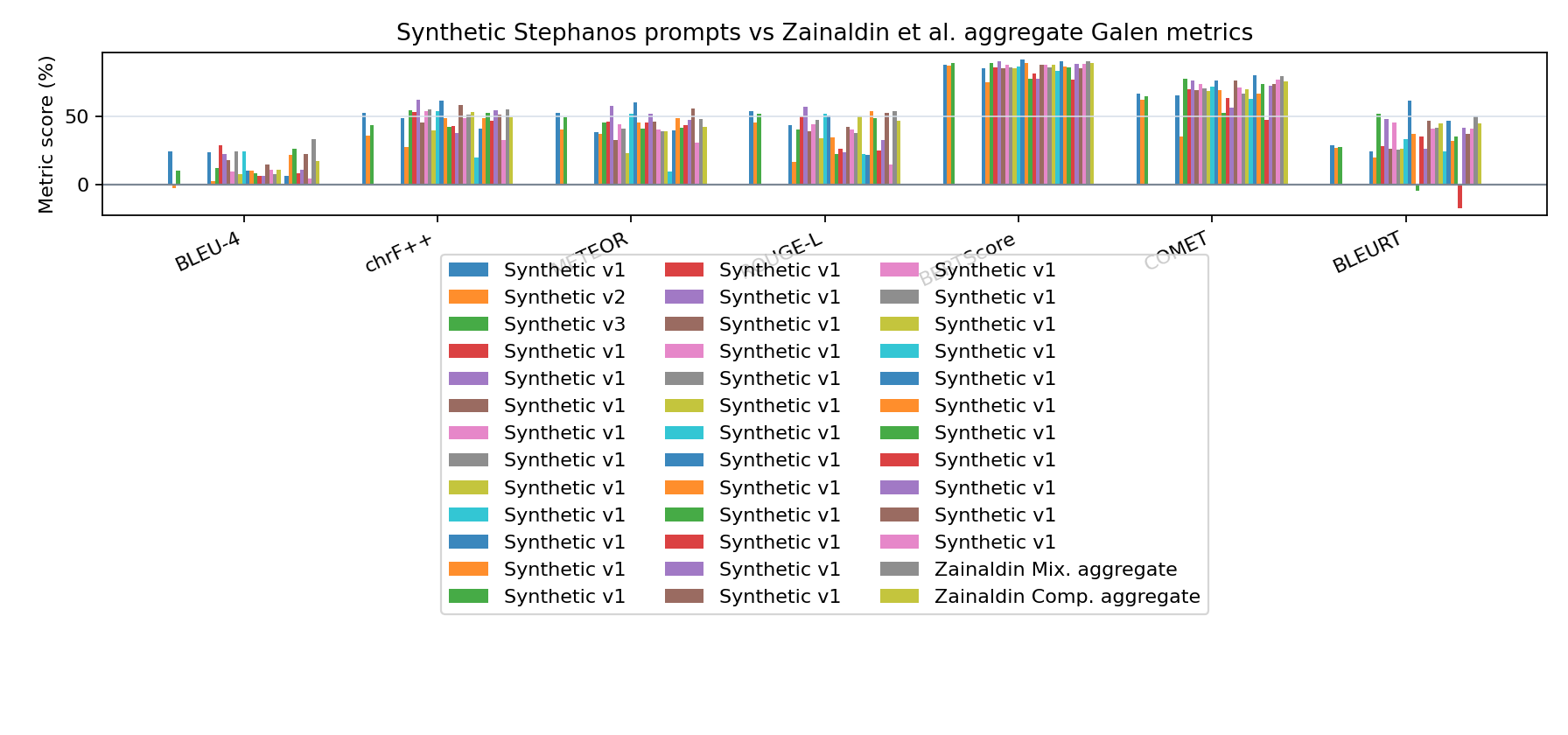
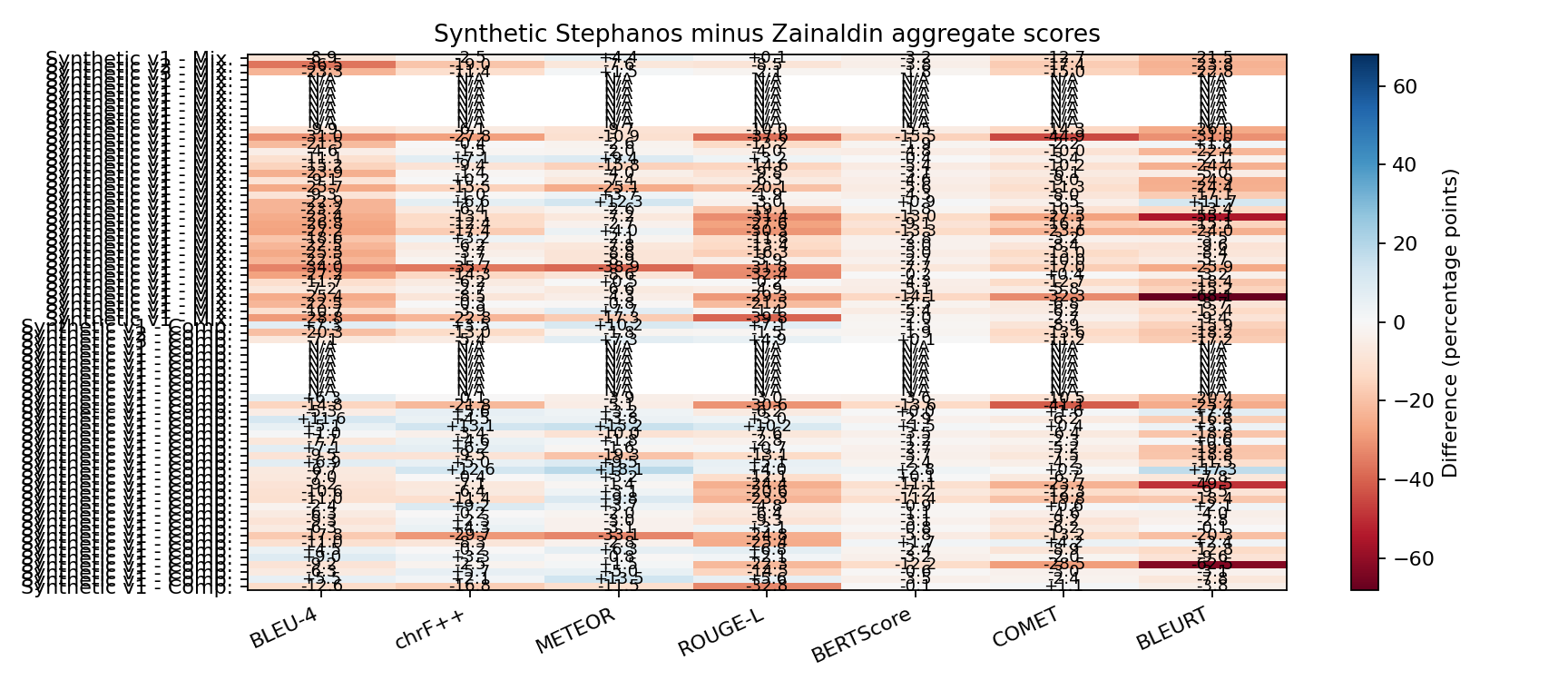
| Prompt | Synthetic passage words | Observed source word range | Extrapolated? | BLEU-4 | chrF++ | METEOR | ROUGE-L | BERTScore | COMET | BLEURT |
|---|---|---|---|---|---|---|---|---|---|---|
| claude_fable_5 v1 | 220.5 | 5.000-181.000 | yes | 20.5% | 53.0% | 49.8% | 52.0% | N/A | N/A | N/A |
| claude_fable_5 v2 | 220.5 | 5.000-181.000 | yes | 6.7% | 43.1% | 42.5% | 48.4% | N/A | N/A | N/A |
| claude_fable_5 v3 | 220.5 | 5.000-181.000 | yes | 6.6% | 43.5% | 48.4% | 50.3% | N/A | N/A | N/A |
| claude_opus_4_8 v1 | 220.5 | 5.000-181.000 | yes | 19.9% | 53.9% | 47.3% | 49.4% | N/A | N/A | N/A |
| claude_opus_4_8 v3 | 220.5 | 5.000-181.000 | yes | 0.5% | 41.0% | 39.1% | 42.7% | N/A | N/A | N/A |
| claude_sonnet_5 v1 | 220.5 | 5.000-181.000 | yes | 24.9% | 54.2% | 49.4% | 48.8% | N/A | N/A | N/A |
| claude_sonnet_5 v2 | 220.5 | 5.000-181.000 | yes | 9.0% | 45.7% | 34.0% | 42.0% | N/A | N/A | N/A |
| claude_sonnet_5 v3 | 220.5 | 5.000-181.000 | yes | 1.4% | 41.7% | 41.6% | 42.2% | N/A | N/A | N/A |
| gpt-4-turbo-2024-04-09 v1 | 220.5 | 5.000-181.000 | yes | 20.9% | 51.6% | 35.3% | 46.0% | N/A | N/A | N/A |
| gpt-4-turbo-2024-04-09 v2 | 220.5 | 5.000-181.000 | yes | -18.0% | 27.8% | 16.0% | 24.4% | N/A | N/A | N/A |
| gpt-4-turbo-2024-04-09 v3 | 220.5 | 5.000-181.000 | yes | -2.7% | 38.0% | 25.8% | 32.3% | N/A | N/A | N/A |
| gpt-4.1-2025-04-14 v1 | 220.5 | 5.000-181.000 | yes | 24.4% | 58.3% | 45.6% | 48.7% | N/A | N/A | N/A |
| gpt-4.1-2025-04-14 v2 | 220.5 | 5.000-181.000 | yes | 7.5% | 44.2% | 36.6% | 40.4% | N/A | N/A | N/A |
| gpt-4.1-2025-04-14 v3 | 220.5 | 5.000-181.000 | yes | 4.6% | 41.5% | 35.4% | 37.4% | N/A | N/A | N/A |
| gpt-4o-2024-05-13 v1 | 220.5 | 5.000-181.000 | yes | 14.3% | 35.4% | 24.8% | 29.2% | N/A | N/A | N/A |
| gpt-4o-2024-05-13 v2 | 220.5 | 5.000-181.000 | yes | 1.7% | 35.1% | 26.7% | 32.4% | N/A | N/A | N/A |
| gpt-4o-2024-05-13 v3 | 220.5 | 5.000-181.000 | yes | -0.9% | 33.8% | 25.1% | 31.5% | N/A | N/A | N/A |
| gpt-4o-2024-08-06 v1 | 220.5 | 5.000-181.000 | yes | 16.2% | 49.7% | 38.2% | 41.0% | N/A | N/A | N/A |
| gpt-4o-2024-08-06 v2 | 220.5 | 5.000-181.000 | yes | 2.1% | 38.7% | 28.1% | 35.5% | N/A | N/A | N/A |
| gpt-4o-2024-08-06 v3 | 220.5 | 5.000-181.000 | yes | -2.2% | 37.4% | 31.1% | 32.7% | N/A | N/A | N/A |
| gpt-4o-2024-11-20 v1 | 220.5 | 5.000-181.000 | yes | 11.2% | 48.5% | 30.3% | 36.5% | N/A | N/A | N/A |
| gpt-4o-2024-11-20 v2 | 220.5 | 5.000-181.000 | yes | 1.9% | 39.0% | 27.9% | 38.1% | N/A | N/A | N/A |
| gpt-4o-2024-11-20 v3 | 220.5 | 5.000-181.000 | yes | -0.2% | 41.5% | 31.5% | 34.2% | N/A | N/A | N/A |
| gpt-5 v1 | 220.5 | 5.000-181.000 | yes | 25.2% | 54.6% | 49.5% | 53.0% | N/A | N/A | N/A |
| gpt-5 v2 | 220.5 | 5.000-181.000 | yes | -2.7% | 35.8% | 32.1% | 44.2% | N/A | N/A | N/A |
| gpt-5 v3 | 220.5 | 5.000-181.000 | yes | 3.7% | 41.0% | 31.2% | 42.0% | N/A | N/A | N/A |
| gpt-5.1 v1 | 220.5 | 5.000-181.000 | yes | 30.1% | 58.1% | 54.4% | 50.0% | N/A | N/A | N/A |
| gpt-5.1 v2 | 220.5 | 5.000-181.000 | yes | 7.3% | 44.1% | 37.7% | 45.9% | N/A | N/A | N/A |
| gpt-5.1 v3 | 220.5 | 5.000-181.000 | yes | 8.6% | 45.4% | 37.9% | 41.2% | N/A | N/A | N/A |
| gpt-5.2 v1 | 220.5 | 5.000-181.000 | yes | 15.7% | 47.2% | 42.6% | 50.7% | N/A | N/A | N/A |
| gpt-5.2 v2 | 220.5 | 5.000-181.000 | yes | -3.3% | 33.0% | 34.4% | 43.7% | N/A | N/A | N/A |
| gpt-5.2 v3 | 220.5 | 5.000-181.000 | yes | 7.8% | 44.4% | 47.4% | 50.6% | N/A | N/A | N/A |
| gpt-5.3-chat-latest v1 | 220.5 | 5.000-181.000 | yes | 24.9% | 55.2% | 57.3% | 56.0% | N/A | N/A | N/A |
| gpt-5.3-chat-latest v2 | 220.5 | 5.000-181.000 | yes | 1.2% | 37.3% | 36.1% | 45.0% | N/A | N/A | N/A |
| gpt-5.3-chat-latest v3 | 220.5 | 5.000-181.000 | yes | 6.4% | 41.6% | 44.9% | 46.9% | N/A | N/A | N/A |
| gpt-5.4 v1 | 220.5 | 5.000-181.000 | yes | 30.6% | 55.3% | 51.6% | 53.0% | N/A | N/A | N/A |
| gpt-5.4 v2 | 220.5 | 5.000-181.000 | yes | 3.8% | 42.2% | 39.6% | 42.6% | N/A | N/A | N/A |
| gpt-5.4 v3 | 220.5 | 5.000-181.000 | yes | 3.6% | 44.5% | 44.9% | 47.8% | N/A | N/A | N/A |
| gpt-5.5 v1 | 220.5 | 5.000-181.000 | yes | 24.9% | 53.2% | 54.1% | 55.2% | N/A | N/A | N/A |
| gpt-5.5 v2 | 220.5 | 5.000-181.000 | yes | -3.1% | 36.2% | 40.7% | 45.5% | N/A | N/A | N/A |
| gpt-5.5 v3 | 220.5 | 5.000-181.000 | yes | 9.7% | 43.6% | 49.8% | 51.8% | N/A | N/A | N/A |
| gpt-5.5_v4_mini v1 | 220.5 | 5.000-181.000 | yes | -7.1% | 33.1% | 23.5% | 31.1% | N/A | N/A | N/A |
| gpt-5.5_v4_mini_high v1 | 220.5 | 5.000-181.000 | yes | -1.4% | 39.5% | 32.1% | 35.8% | N/A | N/A | N/A |
| gpt-5.5_v4_mini_medium v1 | 220.5 | 5.000-181.000 | yes | 3.6% | 40.3% | 32.7% | 38.3% | N/A | N/A | N/A |
| gpt-5.5_v4_reasoning v1 | 220.5 | 5.000-79.000 | yes | -41.9% | 17.9% | 34.1% | 31.6% | N/A | N/A | N/A |
| gpt-5.5_v4_reasoning_high v1 | 220.5 | 5.000-79.000 | yes | -53.6% | 14.4% | 13.9% | 24.9% | N/A | N/A | N/A |
| gpt-5.5_v4_reasoning_medium v1 | 220.5 | 5.000-79.000 | yes | -66.0% | 8.6% | 7.8% | 20.6% | N/A | N/A | N/A |
| gpt-5.6-sol v1 | 220.5 | 5.000-181.000 | yes | 15.8% | 53.2% | 44.8% | 50.3% | N/A | N/A | N/A |
| gpt-5.6-sol v2 | 220.5 | 5.000-181.000 | yes | 1.4% | 38.3% | 40.7% | 46.3% | N/A | N/A | N/A |
| gpt-5.6-sol v3 | 220.5 | 5.000-181.000 | yes | -2.0% | 39.0% | 42.7% | 46.5% | N/A | N/A | N/A |
| legacy_scholarly v3 | 220.5 | 5.000-181.000 | yes | 2.1% | 40.7% | 42.1% | 45.5% | N/A | N/A | N/A |
| paper_guidance_ablation_gpt56 v1 | 220.5 | 5.000-181.000 | yes | 3.4% | 39.4% | 40.2% | 46.9% | N/A | N/A | N/A |
| paper_guidance_ablation_gpt56 v2 | 220.5 | 5.000-181.000 | yes | -4.0% | 35.7% | 36.1% | 42.3% | N/A | N/A | N/A |
| paper_guidance_ablation_gpt56 v3 | 220.5 | 5.000-181.000 | yes | 1.4% | 39.7% | 43.6% | 46.7% | N/A | N/A | N/A |
Table 1 of Zainaldin et al. 2026 reports these values as mean scores multiplied by 100; the table below displays the same scale as percentages.
| Text | Model | BLEU-4 | chrF++ | METEOR | ROUGE-L | BERTScore | COMET | BLEURT |
|---|---|---|---|---|---|---|---|---|
| Mix. | ChatGPT | 31.4% | 53.4% | 46.4% | 50.9% | 91.0% | 79.9% | 49.8% |
| Mix. | Claude | 34.2% | 55.4% | 48.5% | 55.3% | 91.6% | 79.8% | 50.4% |
| Mix. | Gemini | 34.2% | 57.0% | 50.0% | 56.0% | 91.5% | 80.7% | 51.3% |
| Mix. | Aggregate | 33.3% | 55.3% | 48.3% | 54.1% | 91.4% | 80.1% | 50.5% |
| Comp. | ChatGPT | 15.7% | 47.4% | 40.1% | 45.7% | 89.1% | 75.1% | 42.6% |
| Comp. | Claude | 16.7% | 49.4% | 42.9% | 47.8% | 89.7% | 76.5% | 46.2% |
| Comp. | Gemini | 19.0% | 51.2% | 44.4% | 47.8% | 89.9% | 77.3% | 45.8% |
| Comp. | Aggregate | 17.1% | 49.3% | 42.5% | 47.1% | 89.5% | 76.3% | 44.9% |
| Prompt | First translation | Pairs | Lemmas | Slope | Intercept | R^2 | Slope p | |slope - 1| | BLEU-4 | chrF++ | METEOR | ROUGE-L | BERTScore | COMET | BLEURT | Trigram precision | Trigram recall | Trigram F1 | Trigram Jaccard | Mean abs residual |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| claude_fable_5 v1 | 2026-07-05 | 100 | 100 | 1.040 | 1.213 | 0.982 | 9.78e-87 | 0.040 | 27.5% | 58.3% | 66.0% | 67.9% | N/A | N/A | N/A | 25.5% | 27.3% | 26.4% | 15.2% | 3.855 |
| claude_fable_5 v2 | 2026-07-05 | 100 | 100 | 0.909 | 2.460 | 0.985 | 2.28e-91 | 0.091 | 54.3% | 74.4% | 78.1% | 79.1% | N/A | N/A | N/A | 44.1% | 42.4% | 43.2% | 27.6% | 2.869 |
| claude_fable_5 v3 | 2026-07-03 | 100 | 100 | 0.958 | 1.137 | 0.990 | 4.94e-99 | 0.042 | 58.2% | 77.4% | 81.9% | 82.1% | N/A | N/A | N/A | 49.9% | 49.0% | 49.4% | 32.8% | 2.592 |
| claude_opus_4_8 v1 | 2026-07-05 | 100 | 100 | 1.126 | 2.917 | 0.975 | 5.91e-80 | 0.126 | 20.5% | 53.7% | 61.5% | 61.3% | N/A | N/A | N/A | 18.9% | 22.7% | 20.6% | 11.5% | 5.150 |
| claude_opus_4_8 v3 | 2026-07-05 | 100 | 100 | 0.957 | 1.190 | 0.988 | 2.67e-95 | 0.043 | 54.1% | 75.0% | 80.8% | 81.4% | N/A | N/A | N/A | 46.6% | 45.8% | 46.2% | 30.1% | 2.672 |
| claude_sonnet_5 v1 | 2026-07-03 | 100 | 100 | 1.023 | 2.775 | 0.979 | 2.57e-84 | 0.023 | 21.0% | 53.0% | 62.3% | 62.2% | N/A | N/A | N/A | 20.6% | 22.5% | 21.5% | 12.1% | 3.829 |
| claude_sonnet_5 v2 | 2026-07-03 | 100 | 100 | 0.919 | 1.765 | 0.984 | 6.85e-90 | 0.081 | 47.2% | 69.6% | 75.3% | 76.6% | N/A | N/A | N/A | 40.4% | 38.7% | 39.5% | 24.6% | 2.870 |
| claude_sonnet_5 v3 | 2026-07-05 | 100 | 100 | 0.954 | 1.018 | 0.990 | 8.01e-100 | 0.046 | 54.6% | 74.8% | 81.5% | 81.8% | N/A | N/A | N/A | 48.5% | 47.4% | 48.0% | 31.5% | 2.439 |
| gpt-4-turbo-2024-04-09 v1 | 2026-07-16 | 100 | 100 | 0.898 | 6.911 | 0.964 | 1.04e-72 | 0.102 | 17.5% | 47.9% | 53.0% | 53.8% | N/A | N/A | N/A | 15.6% | 16.5% | 16.0% | 8.7% | 4.561 |
| gpt-4-turbo-2024-04-09 v2 | 2026-07-16 | 100 | 100 | 0.888 | 3.076 | 0.982 | 9.56e-87 | 0.112 | 40.0% | 64.5% | 68.7% | 70.7% | N/A | N/A | N/A | 31.0% | 29.6% | 30.3% | 17.9% | 3.356 |
| gpt-4-turbo-2024-04-09 v3 | 2026-07-16 | 100 | 100 | 0.921 | 3.589 | 0.976 | 4.10e-81 | 0.079 | 35.8% | 63.0% | 68.1% | 68.6% | N/A | N/A | N/A | 28.3% | 28.3% | 28.3% | 16.5% | 4.128 |
| gpt-4.1-2025-04-14 v1 | 2026-07-16 | 100 | 100 | 0.999 | 4.615 | 0.977 | 7.20e-82 | 0.001 | 19.6% | 51.2% | 56.9% | 58.7% | N/A | N/A | N/A | 17.7% | 19.7% | 18.7% | 10.3% | 4.568 |
| gpt-4.1-2025-04-14 v2 | 2026-07-16 | 100 | 100 | 0.948 | 1.757 | 0.988 | 2.53e-95 | 0.052 | 41.2% | 66.0% | 72.4% | 73.1% | N/A | N/A | N/A | 35.0% | 34.6% | 34.8% | 21.1% | 2.918 |
| gpt-4.1-2025-04-14 v3 | 2026-07-16 | 100 | 100 | 0.977 | 0.980 | 0.989 | 3.91e-98 | 0.023 | 43.7% | 68.4% | 75.6% | 75.7% | N/A | N/A | N/A | 38.1% | 38.0% | 38.1% | 23.5% | 2.973 |
| gpt-4o-2024-05-13 v1 | 2026-07-16 | 100 | 100 | 0.637 | 16.785 | 0.594 | 6.89e-21 | 0.363 | 19.8% | 50.2% | 55.3% | 57.2% | N/A | N/A | N/A | 17.5% | 17.8% | 17.7% | 9.7% | 11.343 |
| gpt-4o-2024-05-13 v2 | 2026-07-16 | 100 | 100 | 0.835 | 4.383 | 0.914 | 4.78e-54 | 0.165 | 39.7% | 64.3% | 69.5% | 71.8% | N/A | N/A | N/A | 33.7% | 31.4% | 32.5% | 19.4% | 4.523 |
| gpt-4o-2024-05-13 v3 | 2026-07-16 | 100 | 100 | 0.880 | 3.606 | 0.913 | 9.98e-54 | 0.120 | 41.5% | 66.9% | 72.7% | 74.3% | N/A | N/A | N/A | 36.9% | 35.4% | 36.1% | 22.0% | 4.433 |
| gpt-4o-2024-08-06 v1 | 2026-07-16 | 100 | 100 | 0.965 | 5.570 | 0.977 | 4.46e-82 | 0.035 | 18.4% | 49.7% | 54.3% | 56.1% | N/A | N/A | N/A | 15.6% | 17.1% | 16.3% | 8.9% | 4.211 |
| gpt-4o-2024-08-06 v2 | 2026-07-16 | 100 | 100 | 0.922 | 2.240 | 0.983 | 6.39e-89 | 0.078 | 38.7% | 64.7% | 70.8% | 72.3% | N/A | N/A | N/A | 31.6% | 30.7% | 31.2% | 18.5% | 3.183 |
| gpt-4o-2024-08-06 v3 | 2026-07-16 | 100 | 100 | 0.939 | 1.866 | 0.982 | 7.31e-88 | 0.061 | 42.4% | 67.2% | 73.5% | 74.6% | N/A | N/A | N/A | 36.7% | 36.0% | 36.4% | 22.2% | 3.633 |
| gpt-4o-2024-11-20 v1 | 2026-07-16 | 100 | 100 | 1.050 | 4.802 | 0.966 | 4.63e-74 | 0.050 | 16.5% | 49.0% | 54.7% | 54.6% | N/A | N/A | N/A | 13.2% | 15.4% | 14.3% | 7.7% | 5.150 |
| gpt-4o-2024-11-20 v2 | 2026-07-16 | 100 | 100 | 0.900 | 3.578 | 0.975 | 1.46e-80 | 0.100 | 40.2% | 65.8% | 71.4% | 72.4% | N/A | N/A | N/A | 33.1% | 32.4% | 32.8% | 19.6% | 3.650 |
| gpt-4o-2024-11-20 v3 | 2026-07-16 | 100 | 100 | 0.982 | 0.907 | 0.988 | 2.58e-95 | 0.018 | 42.5% | 67.3% | 73.4% | 73.9% | N/A | N/A | N/A | 35.1% | 35.1% | 35.1% | 21.3% | 3.117 |
| gpt-5 v1 | 2026-07-15 | 100 | 100 | 0.981 | 2.837 | 0.980 | 8.03e-85 | 0.019 | 20.7% | 51.9% | 60.4% | 61.8% | N/A | N/A | N/A | 21.0% | 22.0% | 21.5% | 12.0% | 4.084 |
| gpt-5 v2 | 2026-07-15 | 100 | 100 | 0.821 | 4.469 | 0.968 | 2.60e-75 | 0.179 | 47.7% | 70.0% | 74.5% | 76.2% | N/A | N/A | N/A | 40.4% | 37.2% | 38.7% | 24.0% | 3.641 |
| gpt-5 v3 | 2026-07-15 | 100 | 100 | 0.902 | 2.070 | 0.986 | 2.93e-92 | 0.098 | 49.1% | 72.3% | 78.2% | 79.2% | N/A | N/A | N/A | 45.1% | 42.7% | 43.9% | 28.1% | 2.875 |
| gpt-5.1 v1 | 2026-07-15 | 100 | 100 | 1.131 | 0.345 | 0.987 | 5.31e-94 | 0.131 | 20.3% | 51.9% | 59.5% | 60.2% | N/A | N/A | N/A | 20.6% | 23.5% | 21.9% | 12.3% | 3.802 |
| gpt-5.1 v2 | 2026-07-15 | 100 | 100 | 0.966 | 1.024 | 0.990 | 1.67e-99 | 0.034 | 45.3% | 68.7% | 73.5% | 74.6% | N/A | N/A | N/A | 37.9% | 37.5% | 37.7% | 23.2% | 2.670 |
| gpt-5.1 v3 | 2026-07-15 | 100 | 100 | 1.005 | 0.807 | 0.989 | 4.57e-97 | 0.005 | 46.2% | 70.7% | 76.8% | 76.7% | N/A | N/A | N/A | 39.8% | 40.7% | 40.3% | 25.2% | 3.060 |
| gpt-5.2 v1 | 2026-02-14 | 100 | 100 | 1.011 | 5.096 | 0.983 | 1.12e-88 | 0.011 | 23.4% | 53.9% | 58.7% | 58.5% | N/A | N/A | N/A | 18.2% | 20.6% | 19.3% | 10.7% | 3.993 |
| gpt-5.2 v2 | 2026-07-15 | 100 | 100 | 0.922 | 1.802 | 0.988 | 1.29e-95 | 0.078 | 48.1% | 70.4% | 75.6% | 76.0% | N/A | N/A | N/A | 40.0% | 38.4% | 39.2% | 24.4% | 2.701 |
| gpt-5.2 v3 | 2026-07-15 | 100 | 100 | 0.980 | 0.697 | 0.990 | 3.82e-100 | 0.020 | 46.6% | 69.9% | 77.1% | 77.3% | N/A | N/A | N/A | 42.0% | 41.8% | 41.9% | 26.5% | 2.643 |
| gpt-5.3-chat-latest v1 | 2026-07-15 | 100 | 100 | 0.987 | 3.014 | 0.962 | 3.74e-71 | 0.013 | 23.0% | 52.8% | 59.5% | 61.1% | N/A | N/A | N/A | 22.1% | 23.4% | 22.7% | 12.8% | 4.012 |
| gpt-5.3-chat-latest v2 | 2026-07-15 | 100 | 100 | 0.889 | 3.029 | 0.984 | 5.01e-90 | 0.111 | 48.1% | 69.8% | 75.2% | 76.2% | N/A | N/A | N/A | 40.8% | 39.0% | 39.9% | 24.9% | 3.182 |
| gpt-5.3-chat-latest v3 | 2026-07-15 | 100 | 100 | 0.932 | 2.214 | 0.987 | 5.68e-94 | 0.068 | 48.3% | 70.1% | 76.7% | 77.4% | N/A | N/A | N/A | 42.9% | 42.1% | 42.5% | 26.9% | 3.182 |
| gpt-5.4 v1 | 2026-07-14 | 100 | 100 | 0.978 | 2.550 | 0.988 | 4.38e-95 | 0.022 | 23.2% | 52.7% | 57.5% | 60.1% | N/A | N/A | N/A | 21.0% | 21.7% | 21.3% | 11.9% | 3.238 |
| gpt-5.4 v2 | 2026-07-14 | 100 | 100 | 0.940 | 1.708 | 0.984 | 1.12e-89 | 0.060 | 46.8% | 69.7% | 76.5% | 77.2% | N/A | N/A | N/A | 40.5% | 39.6% | 40.1% | 25.1% | 3.023 |
| gpt-5.4 v3 | 2026-07-14 | 100 | 100 | 0.963 | 1.328 | 0.989 | 4.03e-97 | 0.037 | 52.7% | 74.1% | 79.9% | 79.6% | N/A | N/A | N/A | 45.6% | 45.3% | 45.5% | 29.4% | 2.927 |
| gpt-5.5 v1 | 2026-06-17 | 100 | 100 | 1.003 | 2.607 | 0.985 | 1.94e-91 | 0.003 | 25.1% | 53.7% | 56.0% | 58.4% | N/A | N/A | N/A | 20.1% | 21.4% | 20.7% | 11.6% | 3.562 |
| gpt-5.5 v2 | 2026-06-07 | 100 | 100 | 0.888 | 2.957 | 0.981 | 4.12e-86 | 0.112 | 51.9% | 72.4% | 77.3% | 78.0% | N/A | N/A | N/A | 43.3% | 41.3% | 42.3% | 26.8% | 3.084 |
| gpt-5.5 v3 | 2026-05-07 | 100 | 100 | 0.929 | 2.247 | 0.986 | 2.62e-93 | 0.071 | 57.6% | 77.2% | 80.8% | 81.2% | N/A | N/A | N/A | 50.0% | 49.0% | 49.5% | 32.9% | 2.986 |
| gpt-5.5_v4_mini v1 | 2026-06-25 | 100 | 100 | 0.937 | 1.347 | 0.989 | 2.58e-97 | 0.063 | 42.4% | 67.0% | 72.7% | 74.4% | N/A | N/A | N/A | 36.3% | 35.1% | 35.7% | 21.7% | 2.841 |
| gpt-5.5_v4_mini_high v1 | 2026-06-28 | 100 | 100 | 0.892 | 2.395 | 0.985 | 1.38e-91 | 0.108 | 46.6% | 70.0% | 76.0% | 77.8% | N/A | N/A | N/A | 41.0% | 38.7% | 39.8% | 24.8% | 2.990 |
| gpt-5.5_v4_mini_medium v1 | 2026-06-27 | 100 | 100 | 0.898 | 2.083 | 0.985 | 1.31e-90 | 0.102 | 45.6% | 69.2% | 75.7% | 77.3% | N/A | N/A | N/A | 40.8% | 38.4% | 39.6% | 24.7% | 2.846 |
| gpt-5.5_v4_reasoning v1 | 2026-06-21 | 42 | 42 | 0.936 | 0.997 | 0.986 | 2.02e-38 | 0.064 | 60.9% | 79.0% | 83.8% | 84.0% | N/A | N/A | N/A | 53.6% | 51.7% | 52.7% | 35.7% | 1.811 |
| gpt-5.5_v4_reasoning_high v1 | 2026-06-24 | 32 | 32 | 0.923 | 1.570 | 0.986 | 1.35e-29 | 0.077 | 59.9% | 78.5% | 82.4% | 82.4% | N/A | N/A | N/A | 48.2% | 46.8% | 47.5% | 31.1% | 1.914 |
| gpt-5.5_v4_reasoning_medium v1 | 2026-06-23 | 32 | 32 | 0.948 | 0.531 | 0.992 | 6.16e-33 | 0.052 | 63.7% | 80.5% | 84.6% | 84.9% | N/A | N/A | N/A | 53.1% | 51.1% | 52.1% | 35.2% | 1.597 |
| gpt-5.6-sol v1 | 2026-07-14 | 100 | 100 | 0.998 | 3.126 | 0.974 | 1.50e-79 | 0.002 | 23.3% | 51.8% | 56.0% | 57.7% | N/A | N/A | N/A | 18.7% | 20.1% | 19.4% | 10.7% | 4.295 |
| gpt-5.6-sol v2 | 2026-07-14 | 100 | 100 | 0.925 | 2.075 | 0.988 | 1.19e-96 | 0.075 | 52.3% | 72.9% | 77.4% | 77.4% | N/A | N/A | N/A | 42.7% | 41.4% | 42.0% | 26.6% | 2.711 |
| gpt-5.6-sol v3 | 2026-07-14 | 100 | 100 | 0.925 | 2.557 | 0.985 | 2.53e-91 | 0.075 | 55.5% | 75.4% | 80.4% | 80.4% | N/A | N/A | N/A | 47.0% | 46.1% | 46.6% | 30.3% | 3.006 |
| legacy_scholarly v3 | 2026-05-07 | 100 | 100 | 0.926 | 1.967 | 0.986 | 4.54e-93 | 0.074 | 52.7% | 73.3% | 76.4% | 78.0% | N/A | N/A | N/A | 42.6% | 41.3% | 41.9% | 26.5% | 2.765 |
| paper_guidance_ablation_gpt56 v1 | 2026-07-18 | 100 | 100 | 0.919 | 2.272 | 0.987 | 1.42e-94 | 0.081 | 51.9% | 72.7% | 77.0% | 77.6% | N/A | N/A | N/A | 42.7% | 41.4% | 42.0% | 26.6% | 2.790 |
| paper_guidance_ablation_gpt56 v2 | 2026-07-18 | 100 | 100 | 0.909 | 2.955 | 0.983 | 2.24e-88 | 0.091 | 51.4% | 72.4% | 76.6% | 77.3% | N/A | N/A | N/A | 41.7% | 40.6% | 41.1% | 25.9% | 3.072 |
| paper_guidance_ablation_gpt56 v3 | 2026-07-18 | 100 | 100 | 0.947 | 1.719 | 0.989 | 1.20e-97 | 0.053 | 55.9% | 75.6% | 81.5% | 80.8% | N/A | N/A | N/A | 47.8% | 47.2% | 47.5% | 31.1% | 2.719 |